한 줄 정의 : 다중 카메라 이미지 기반으로 자율주행 환경의 3D 점유 공간(Occupancy)을 정확하고 조밀하게 예측하는 새로운 방식.
핵심 혁신(Breakthrough)
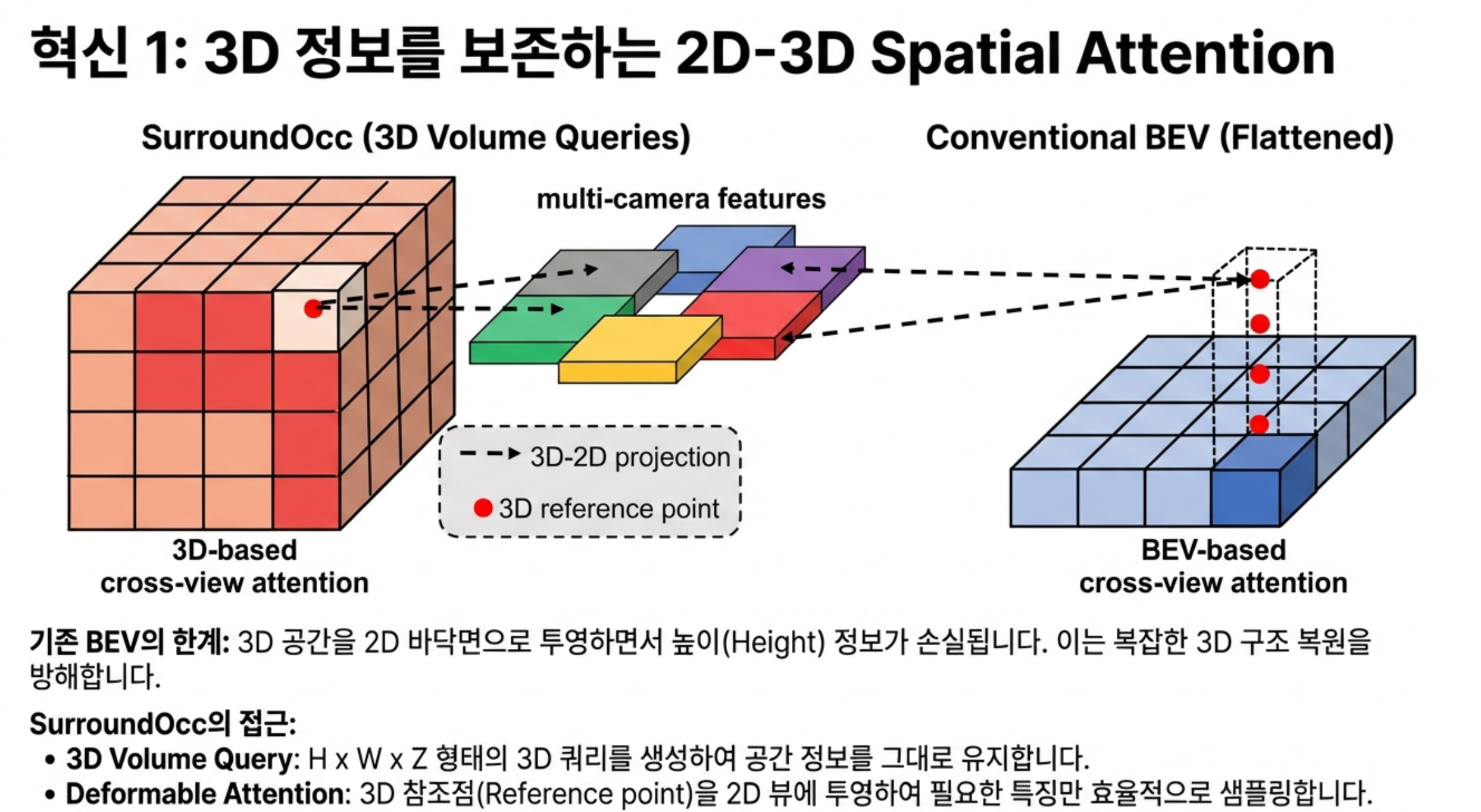
• 2D-3D 공간 어텐션(Spatial Attention) 도입으로 효율적인 멀티 카메라 정보 융합.
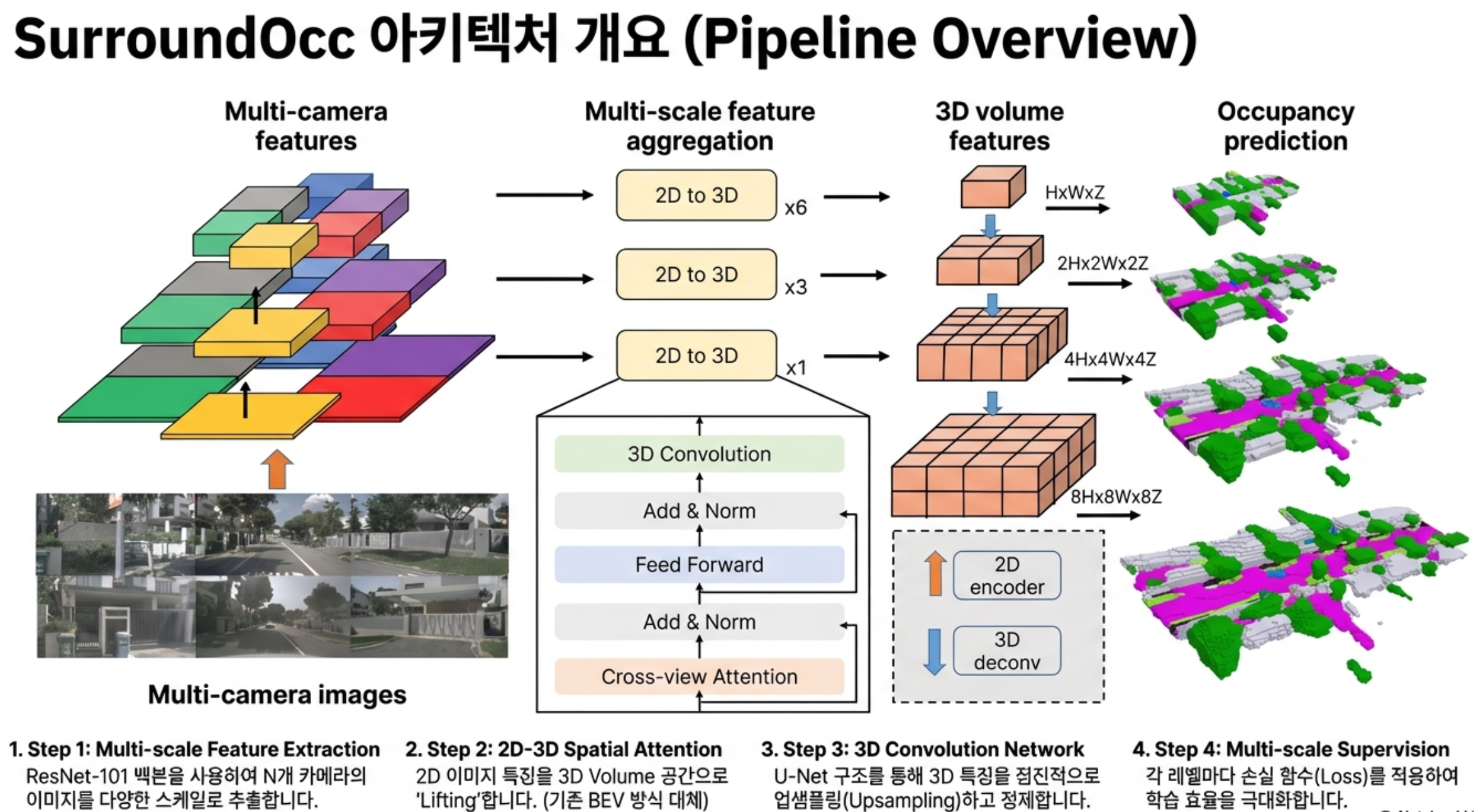
1. 멀티 스케일 이미지 특징(Multi-scale Image Features)을 3D 볼륨 공간(3D Volume Space)으로 직접 변환.
2. 기존 BEV(Bird's-Eye-View) 방식 대비 3D 공간 정보를 더 잘 보존하여, 가려진 영역까지 복원 가능.
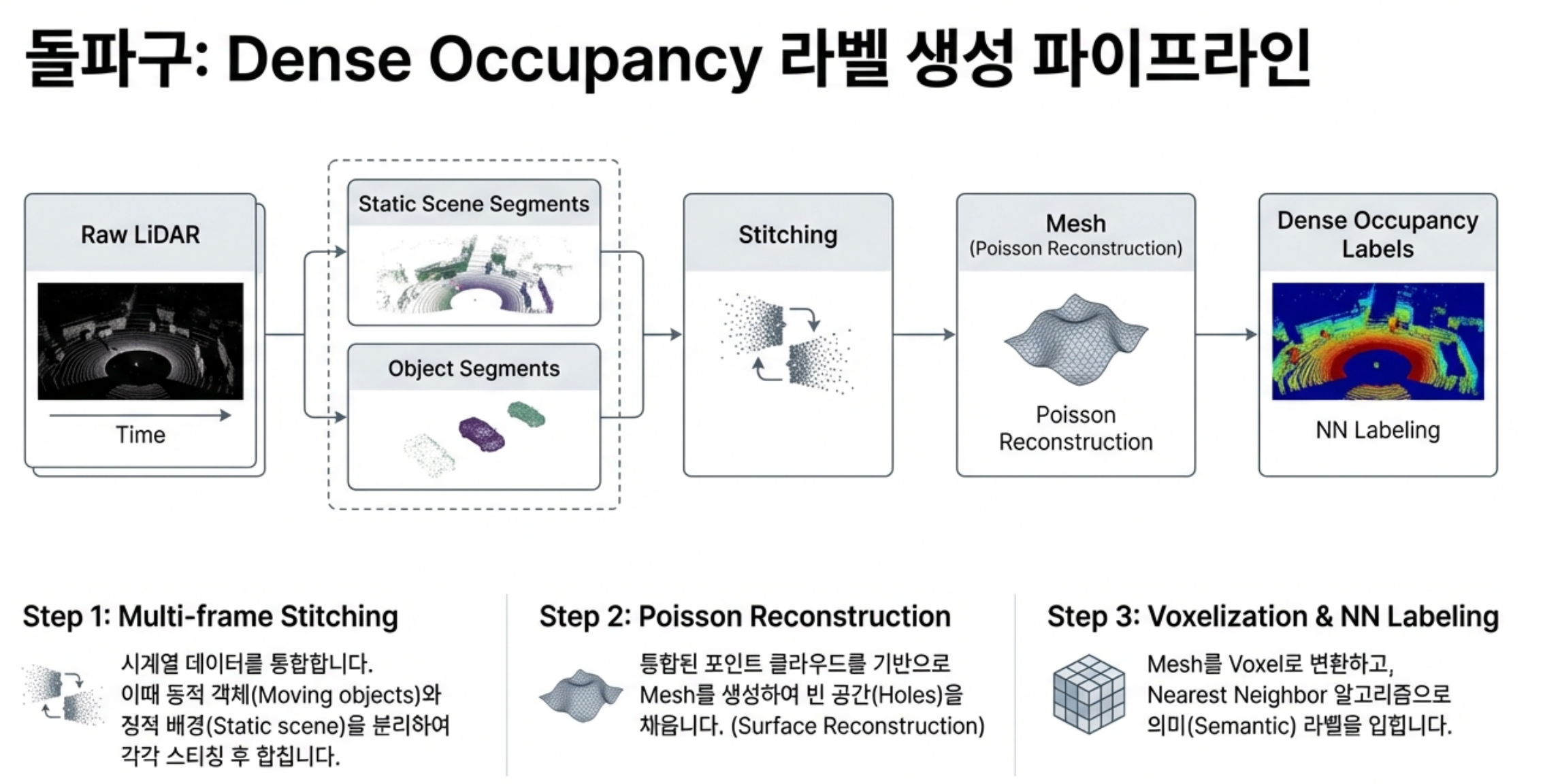
• 조밀한 3D 점유 공간 GT(Ground Truth) 생성 파이프라인 설계로 학습 데이터 밀도 문제 해결.
1. 기존의 희소한 LiDAR 포인트와 3D 객체 탐지, 시맨틱 분할(Semantic Segmentation) 라벨 활용.
2. 동적 객체와 정적 장면의 다중 프레임 LiDAR 스캔을 분리 융합하고, 푸아송 재구성(Poisson Reconstruction)으로 구멍을 채워 매우 조밀한 점유 공간 라벨 자동 생성.
• 멀티 스케일 점유 공간 예측(Multi-scale Occupancy Prediction) 아키텍처로 세밀한 3D 표현 학습.
1. 3D 컨볼루션 네트워크(3D Convolution Network)를 사용해 저해상도 볼륨 특징을 점진적으로 업샘플링하고 고해상도 특징과 융합
2. 각 스케일(Level)에서 가중치 감소 손실(Decayed Weighted Loss)로 네트워크를 감독하여 전체적인 성능 향상.